使用Rust编写操作系统 - 1.2 - 最小化Rust内核
在这篇文章中,我们将为x86架构创建一个最小化的64位Rust内核。我们将在上一篇文章的独立Rust二进制程序基础上,创建一个可启动的磁盘映像,并在屏幕上打印一些东西。
这个博客是在GitHub上公开开发的。如果你有任何问题或疑问,请在那里开一个issue。你也可以在底部留言。这篇文章的完整源代码可以在post-02分支中找到。
启动过程
当您打开计算机时,它开始执行存储在主板ROM中的固件代码。这段代码会执行开机自检,检测可用的RAM,并对CPU和硬件进行预初始化。之后,它寻找一个可启动的磁盘,并开始启动操作系统内核。
在x86上,有两种固件标准:”基本输入/输出系统”(BIOS)和较新的 “统一可扩展固件接口”(UEFI)。BIOS标准虽然老旧过时,却较为简单,而且自20世纪80年代以来在任何x86机器上都得到了良好的支持。相比之下,UEFI更现代,功能更多,但设置起来更复杂(至少在我看来)。
目前,我们只提供BIOS支持,但对UEFI的支持也在计划之中。如果你愿意帮助我们,请查看Github issue。
BIOS启动
几乎所有的x86系统都支持BIOS启动,包括使用模拟BIOS的较新的基于UEFI的机器。这是很好的,因为你可以在上世纪的所有机器上使用相同的启动逻辑。但这种广泛的兼容性同时也是BIOS启动的最大缺点,因为这意味着CPU在启动前会被放入一个叫做实模式的16位兼容模式,这样上世纪80年代的老式引导程序仍然可以使用。
让我们从头说起。
当你打开电脑时,它会从位于主板上的一些特殊闪存中加载BIOS。BIOS会运行硬件的自我测试和初始化例程,然后寻找可启动磁盘。如果它找到了一个,控制权就会转移到它的bootloader,这是存储在磁盘开头的512字节的可执行代码部分。大多数的引导加载器都大于512字节,所以引导加载器通常被分成一个小的第一阶段引导程序——刚好512字节——和一个第二阶段引导程序——在第一阶段引导程序之后加载。
引导程序必须确定内核映像在磁盘上的位置,并将其加载到内存中。它还需要先将CPU从16位的实模式切换到32位的保护模式,然后再切换到64位的长模式,在长模式下可以使用64位寄存器和完整的主内存。它的j第三项工作是从BIOS中查询某些信息(如内存映射),并将其传递给操作系统内核。
编写一个bootloader是有点麻烦的,因为它需要汇编语言和很多非深入的步骤,比如 “把这个魔数值写入这个处理器寄存器”。因此,我们在这篇文章中不涉及bootloader的创建,而是提供了一个名为bootimage的工具,它可以自动将bootloader预置到你的内核中。
如果你对构建自己的bootloader感兴趣。请持续关注,一系列关于这个主题的文章已经在计划中了!
Multiboot标准
为了避免每个操作系统都实现自己的bootloader,而bootloader只能与单一操作系统兼容,自由软件基金会在1995年创建了一个名为Multiboot的开放bootloader标准。该标准定义了引导加载器和操作系统之间的接口,因此任何符合Multiboot标准的引导加载器都可以加载任何符合Multiboot标准的操作系统。参考实现是GNU GRUB,它是Linux系统中最流行的引导加载器。
要使内核符合Multiboot的要求,只需要在内核文件的开头插入一个所谓的Multiboot头。这使得在GRUB中启动一个操作系统变得非常容易。然而,GRUB和Multiboot标准也有一些问题:
- 只支持32位保护模式。这意味着你仍然必须进行CPU配置才能切换到64位长模式。
- 其设计是为了简化bootloader,而不是简化内核。例如,内核需要链接一个调整后的默认页长度,否则GRUB会找不到Multiboot头。另一个例子是,传递给内核的引导信息,包含了很多依赖于架构的结构,而不是提供清晰的抽象。
- GRUB和Multiboot标准的文档支持较少。
- GRUB需要安装在主机系统上才能从内核文件中创建一个可启动的磁盘镜像。这使得在Windows或Mac上的开发更加困难。
鉴于此,我们决定不使用GRUB或Multiboot标准。然而,我们计划在我们的bootimage工具中加入对Multiboot的支持,这样就可以在GRUB系统上加载你的内核。如果你对编写一个符合Multiboot标准的内核感兴趣,请查看本系列博客的第一版。
UEFI
(我们目前不提供UEFI支持,但我们很乐意! 如果你愿意帮忙,请在Github issue中告诉我们。)
最小化内核
现在我们已经大致知道了计算机是如何启动的,现在是时候创建我们自己的最小内核了。我们的目标是创建一个磁盘映像,在启动时向屏幕打印 “Hello World!”。为此,我们在上一篇文章中的独立Rust二进制程序基础上进行开发。
你可能还记得,我们通过cargo构建了独立的二进制文件,但根据不同的操作系统,我们需要不同的入口点名称和编译标识。这是因为cargo默认是为主机系统编译,也就是你正在运行的系统。这并不是我们想要的内核,因为一个运行在Windows之上的内核并没有什么意义。相反,我们希望为一个明确定义的目标系统编译。
安装Rust Nightly
Rust有三个发布频道:稳定版、测试版和nightly版。Rust Book很好地解释了这些频道之间的区别,所以花点时间看看吧。为了构建一个操作系统,我们需要一些实验性的功能,而这些功能只有在nightly频道上才有,所以我们需要安装一个nightly版本的Rust。
要管理Rust的安装,我强烈推荐rustup。它允许你并排安装nightly、测试版和稳定版编译器,并使其易于更新。使用rustup,你可以通过运行rustup override set nightly为当前目录使用夜间编译器。或者,你也可以在项目的根目录下添加一个名为rust-toolchain的文件,其内容为nightly。你可以通过运行rustc --version来检查你是否安装了nightly版本。版本号的末尾应该包含-nightly。
nightly编译器允许我们通过在文件顶部使用所谓的特征标识来选择加入各种实验性特征。例如,我们可以通过在main.rs的顶部添加#![feature(asm)]来启用内联汇编的实验性asm!宏。请注意,这种实验性的特性是完全不稳定的,这意味着未来的Rust版本可能会在没有事先警告的情况下更改或删除它们。因此,我们只有在绝对必要的情况下才会使用它们。
目标配置清单
cargo通过--target参数支持不同的目标系统。目标由所谓的目标系统三元组描述,它描述了CPU架构、厂商、操作系统和ABI。例如,x86_64-unknown-linux-gnu目标三元组描述了一个具有x86_64 CPU、没有明确的供应商、且具有GNU ABI的Linux操作系统的目标系统。Rust支持许多不同的目标三元组,包括Android的arm-linux-androideabi或WebAssembly的wasm32-unknown-unknown。
然而,对于我们的目标系统,我们需要一些特殊的配置参数(比如没有底层操作系统),所以现有的目标三元组都不适合。幸运的是,Rust允许我们通过JSON文件来定义自己的目标三元组。例如,一个描述x86_64-unknown-linux-gnu目标的JSON文件是大概这样的:
1 | { |
大多数字段是LLVM为该平台生成代码所需要的。例如,data-layout字段定义了各种整数、浮点和指针类型的大小。还有一些Rust用于条件编译的字段,比如target-pointer-width。第三种字段定义了应该如何构建crate。例如,pre-link-args字段指定了传递给链接器的参数。
我们的内核也是以x86_64系统为目标的,所以我们的目标描述文件看起来会和上面的很相似。让我们先创建一个x86_64-blog_os.json文件(选择任何你喜欢的名字),里面有通用的内容有:
1 | { |
请注意,我们将llvm-target中的系统以及os字段中的系统均改为none,因为我们将在裸机上运行。
我们增加以下与build有关的配置项:
1 | "linker-flavor": "ld.lld", |
我们不使用平台的默认链接器(可能不支持Linux目标系统),而是使用Rust自带的跨平台LLD链接器来链接我们的内核。
1 | "panic-strategy": "abort", |
这个设置指定了目标不支持在panic时进行栈展开,因此程序遇到问题时将直接终止。这和我们Cargo.toml中的panic = "abort"选项一样,所以我们可以从那里删除它。(请注意,与Cargo.toml选项不同的是,这个目标选项在我们后面重新编译core库时通用需要。因此,即使你喜欢保留Cargo.toml里的选项,也一定要添加这个选项。)
1 | "disable-redzone": true, |
我们正在编写一个内核,所以我们需要在某些时候处理中断。为了安全起见,我们必须禁用一个叫做“红区”的堆栈指针优化,因为如果不这样做,可能会导致堆栈数据被破坏。更多的信息,请看我们单独的关于禁用红区的文章。
1 | "features": "-mmx,-sse,+soft-float", |
fatures字段启用/禁用目标的CPU指令特性。我们在mmx和sse特性前使用减号来禁用它们,在soft-float特性前加加号来启用它。注意不同标志之间不能有空格,否则LLVM无法解释特性字符串。
mmx和sse特性决定了对单指令多数据(SIMD)指令的支持,这通常可以大大提升程序的速度。然而,在操作系统内核中使用大型SIMD寄存器会导致性能问题。原因是内核需要在继续中断的程序之前将所有寄存器恢复到原来的状态。这意味着内核必须在每次系统调用或硬件中断时将完整的SIMD状态保存到主存中。由于SIMD状态非常大(512-1600字节),而且中断可能会非常频繁地发生,这些额外的保存/恢复操作会大大降低性能。为了避免这种情况,我们禁用了内核的SIMD(并不是禁用运行在其上的应用程序的SIMD特性!)。
禁用SIMD的一个问题是,x86_64上的浮点运算默认需要SIMD寄存器。为了解决这个问题,我们增加了soft-float特性,通过基于普通整数的软件函数来模拟所有的浮点运算。
我们撰写了一篇关于禁用SIMD的短文,以供读者深入了解相关信息。
放在一起
现在,我们的目标系统描述文件现在看起来是这样的:
1 | { |
编译内核
编译我们的新目标系统将使用Linux惯例(我不太确定为什么,我猜这只是LLVM默认如此)。这意味着我们需要一个名为_start的入口点,就像上一篇文章中描述的那样。
1 | // 不链接Rust标准库 |
注意,无论你的主机操作系统如何,这个入口点都需应命名为_start。
现在,我们可以给--target参数传入JSON描述文件来为我们的新目标系统构建内核。
1 | > cargo build --target x86_64-blog_os.json |
编译失败了! 这个错误告诉我们,Rust编译器已经找不到core库了。这个库包含Rust基本类型,如Result、Option、迭代器等,并且隐式地链接到所有no_stdcrates。
这个问题在于,core库是作为预编译库与Rust编译器一起发布的。因此,它只支持预定义的几个目标系统三元组(如x86_64-unknown-linux-gnu),而不支持我们自定义的目标三元组。如果我们想为其他目标编译代码,我们需要先为这些目标重新编译core库。
build-std选项
这就是cargo的build-std选项的作用:它允许按需重新编译core和其他标准库crate,而不是使用Rust安装时附带的预编译版本。这个功能是非常新的,还没有完成,所以它被标记为”unstable”,只在nightly的Rust编译器上可用。
为了使用该特性,我们需要在项目跟目录下新建cargo配置文件.cargo/config.toml,加入内容如下:
1 | [unstable] |
该配置项告诉cargo需要重新编译core和compiler_builtins库,其中compiler_builtins库是编译core库的一个依赖。为了编译这些库,cargo需要读取rust源码,可以通过rustup component add rust-src安装源码组件。
设置好unstable.build-std配置项并安装rust-src源码组件后,就可以重新运行我们的编译命令:
1 | > cargo build --target x86_64-blog_os.json |
我们看到cargo build现在为我们的自定义目标重新编译了core、rustc-std-workspace-core(此为compiler_builtins的依赖)和compiler_builtins库。
内存相关的内联函数
Rust编译器假设,在所有的操作系统中,均提供一组内置函数。其中的大多数函数由我们刚才编译的compiler_builtinscrate提供。不过,该crate中有一些内存相关的函数,通常由操作系统的C语言库提供,所以默认为不启用。这些函数包括用以将一个内存块中的所有字节设置为一个给定值的memset,用以将一个内存块复制到另一个内存块的memcpy,以及用来比较两个内存块的memcmp。虽然现在编译我们的内核的时候并不需要这些函数,但是当我们添加更多的代码时(例如在复制结构体的时候),就会用到这些函数。
由于我们无法链接到操作系统的C语言库,所以我们需要另一种方式来向编译器提供这些函数。一个可能的方法是实现我们自己的memset等一系列函数,并为它们添加#[no_mangle]标识(用以避免编译过程中的自动重命名)。不过这相当危险,因为在实现这些函数的过程中稍有差错就会导致程序不可预料的行为。例如,当你使用for循环实现memcpy时,你可能会得到一个无限递归,因为for循环隐式地调用IntoIterator::into_itertrait方法,这可能会再次调用memcpy。所以,重用现有的经过良好测试的实现是个好主意。
幸运的是,compiler_builtinscrate已经包含了所有需要的函数的实现,只是为了不与C语言库中的实现相冲突,它们被默认为禁用了。我们可以通过设置 cargo的build-std-features标识为["compiler-builtins-mem"]来启用它们。与build-std标识一样,这个标识可以在命令行中以-Z标志的形式传递,也可以在.cargo/config.toml文件中的”unstable”域中配置。由于我们总是希望用这个标识来构建,所以配置文件选项对我们来说会更方便:
1 | [unstable] |
(compiler-builtins-mem特性是最近才添加的,因此需要2020-09-30后的Rust nightly版本。)
在幕后,这个标志启用了compiler_builtinscrate的mem功能。这样做的效果是,#[no_mangle]属性被应用到crate的memcpy等实现中,使得它们可以被链接器使用。
如此,对编译器要求的所有函数,我们的内核都有了有效的实现,之后即使我们的代码变得更复杂,它也能够通过编译。
设置默认目标
为了避免每次使用cargo xbuild时传递--target参数,我们可以覆写默认的编译目标。继续向cargo配置文件.cargo/config.toml添加以下内容:
1 | [build] |
这里的配置告诉cargo在没有显式声明目标的情况下,使用我们提供的x86_64-blog_os.json作为目标配置。这意味着我们可以直接使用cargo build进行构建。更多关于cargo配置选项的信息,请查看官方文档。
现在我们可以用一个简单的cargo build构建裸金属上的内核了。然而,我们的_start入口点仍然是空的,它将被bootloader调用。是时候输出一些东西到屏幕上了。
在屏幕上打印字符
现阶段将文字打印到屏幕上最简单的方法是使用VGA文字缓冲区。它是一个包含屏幕上显示的内容的特殊的内存区域,直接映射到VGA硬件。它通常由25行组成,每行包含80个字符单元。每个字符单元显示一个ASCII字符,并带有一些前景和背景颜色。屏幕输出的内容是这样的。

我们将在下一篇文章中讨论VGA缓冲区的详情,届时将为它编写第一个小型驱动程序。我们目前仅仅是打印”Hello World!”,只需要知道缓冲区位于地址0xb8000,每个字符单元由一个ASCII字节和一个颜色字节组成。
我们的实现就像这样:
1 | static HELLO: &[u8] = b"Hello World!"; |
首先,我们将整数0xb8000转成一个裸指针。然后,我们对静态HELLO字节字符串的字节进行迭代。我们使用enumerate方法额外获得迭代索引i,在for循环中,我们使用offset方法写入字符串字节和相应的颜色字节(0xb为淡青色)。
请注意,所有的内存写入操作均放置于unsafe块中。原因是Rust编译器无法推断出我们创建的裸指针是有效的。它们可能指向任何地方并导致数据损坏。通过将它们放入unsafe块,我们基本上是在告诉编译器,我们绝对确信这些操作是有效的。请注意,unsafe块并不会关闭Rust的安全检查。它只允许您做五件额外的事情。
我想强调的是,这不是我们想在Rust中做的事情!在不安全的块内处理裸指针时,很容易出乱子,例如,如果我们不小心,很容易写到缓冲区的末端。
所以我们要尽可能的减少unsafe块的使用。Rust通过创建安全抽象给我们提供了这样的能力。例如,我们可以创建一个VGA缓冲类型,封装所有的不安全操作,并确保不可能从外部进行任何错误调用。这样一来,我们就只需要最少的unsafe块,并且可以确保不违反内存安全。我们将在下一篇文章中创建这样一个安全的VGA缓冲区抽象。
启动内核
现在我们已经有了一个可执行文件,并且可以进行一些可见的操作,是时候运行它了。首先,我们需要将我们编译好的内核通过与bootloader连接,变成一个可引导的磁盘镜像。然后,我们可以在QEMU虚拟机中运行磁盘镜像,或者用U盘在真实的硬件上引导它。
创建引导镜像
为了把编译后的内核变成一个可启动的磁盘镜像,我们需要把它和引导程序连接起来。正如我们在启动过程一节中所学到的,引导程序负责初始化CPU和加载内核。
我们不需要编写自己的bootloader,这是一个独立的项目,我们使用bootloader crate。这个crate实现了一个基本的BIOS引导加载器,没有任何C语言的依赖,只有Rust和内联汇编。为了使用它来启动我们的内核,我们需要添加一个依赖。
1 | [dependencies] |
添加bootloader作为依赖,并不足以真正创建一个可启动的磁盘镜像。其中的问题是,我们需要在编译后将内核与bootloader链接起来,但cargo不支持post-build脚本。
为了解决这个问题,我们创建了一个名为bootimage的工具,它首先编译内核和bootloader,然后将它们连接在一起,创建一个可启动的磁盘镜像。要安装这个工具,请在你的终端上执行以下命令:
1 | cargo install bootimage |
为了运行bootimage和构建bootloader,你需要安装llvm-tools-preview rustup组件。你可以通过执行rustup component add llvm-tools-preview来安装。
安装bootimage并添加llvm-tools-preview组件后,我们可以创建可启动磁盘镜像:
1 | > cargo bootimage |
我们看到该工具使用cargo build重新编译我们的内核,所以它会自动获取你所做的任何更改。之后,它会编译bootloader,这可能需要一段时间。像所有的crate依赖一样,它只编译一次,然后进行缓存,所以后续的编译速度会快很多。最后,bootimage将bootloader和你的内核结合成一个可启动的磁盘镜像。
执行该命令后,你应该会在target/x86_64-blog_os/debug目录下看到一个名为bootimage-blog_os.bin的可启动磁盘镜像。你可以在虚拟机中启动它,或者将它复制到USB驱动器中,在真正的硬件上启动它。(注意,这不是CD镜像,因为CD镜像有不同的格式,所以刻录到CD上是不行的)。
它是如何工作的?
bootimage工具在后台执行以下步骤:
- 它将我们的内核编译成ELF文件。
- 它将bootloader的依赖性编译成一个独立的可执行文件。
- 它将内核ELF文件按字节链接到bootloader末尾。
当启动时,bootloader读取并解析附加的ELF文件。然后,它将程序段映射到页表中的虚拟地址,将.bss部分归零,并建立一个堆栈。最后,它读取入口点地址(我们的_start函数)并跳转到它。
在QEMU中启动内核
现在我们可以在虚拟机中启动内核了。为了在QEMU中启动内核,我们使用下面的命令:
1 | > qemu-system-x86_64 -drive format=raw,file=target/x86_64-blog_os/debug/bootimage-blog_os.bin |
这将打开一个单独的窗口与,看起来像这样:
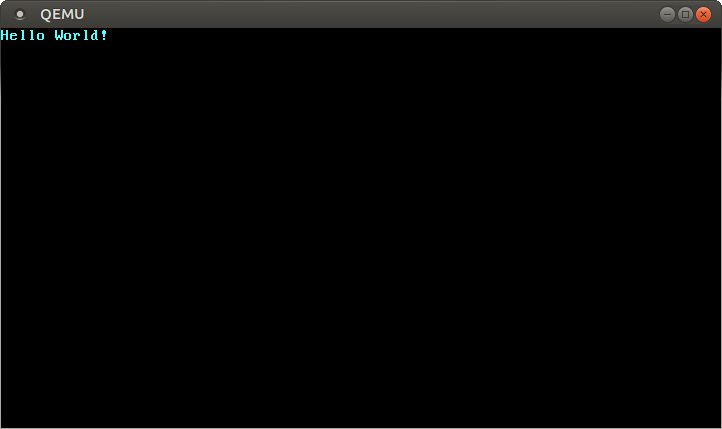
我们看到屏幕上可以看到的”Hello World!”。
在物理机器上运行内核
也可以将其写入U盘,在物理机器上启动:
1 | > dd if=target/x86_64-blog_os/debug/bootimage-blog_os.bin of=/dev/sdX && sync |
其中sdX是你的U盘的设备名。请注意选择正确的设备名称,因为该设备上的所有内容都会被覆盖。
将镜像写入U盘后,就可以通过从U盘启动,并在物理硬件上运行它。你可能需要指定启动项或改变BIOS配置中的启动顺序来从U盘启动。需要注意的是,目前它还不能用于UEFI机器,因为bootloader crate还不支持UEFI。
使用cargo run
为了方便在QEMU中运行我们的内核,可以设置cargo的runner配置键。
要让在QEMU中运行内核更轻松,我们可以设置在cargo配置文件中设置runner配置项:
1 | [target.'cfg(target_os = "none")'] |
target.'cfg(target_os = "none")'域适用于所有将目标系统配置文件的"os"字段设置为"none"的目标系统。这将包括我们的x86_64-blog_os.json目标。runner键指定了cargo run应该调用的命令。该命令是在成功编译后运行的,可执行文件的路径将作为第一个参数传递。更多细节请参见cargo文档。
bootimage runner命令是专门设计用作runner配置项的可执行程序使用的,它将链接给定的可执行程序和项目的bootloader依赖关系,然后启动QEMU。更多细节和可能的配置选项请参见bootimage的Readme。
现在我们可以使用cargo run来编译我们的内核,并在QEMU中启动它。
下期预告
在下一篇文章中,我们将更详细地探讨VGA文本缓冲区,并为它编写一个安全的接口。我们还将添加对println宏的支持。
支持本项目
创建和维护这个博客和相关库是一项繁重的工作,但我真的很喜欢。通过支持我,您可以让我在新内容、新功能和持续维护上投入更多时间。
支持我的最好方式是在GitHub上赞助我,因为他们不收取任何中间费用。如果你喜欢其他平台,我也有Patreon和Donorbox账户。后者是最灵活的,因为它支持多种货币和一次性捐款。
感谢您的支持!

